데이터 준비하는 방법이 궁금하신 분들은 이전 포스팅을 보고 와주세요 :)
https://walkandwork.tistory.com/21
NLP(자연어처리) 화장품 리뷰 분석 (1)_데이터 준비 /크롤링 몰라도 가능
화장품 컨텐츠를 발행하면서, 온라인 제품 리뷰를 분석하면 제품마다 특성을 뚜렷하게 볼 수 있을 것 같아 자연어처리 공부를 시작했습니다. 아직 실수도 많고, 허점도 많지만, 시작이 반이라는
walkandwork.tistory.com
오늘은 어제 정리한 데이터를 통해서
빈도수 분석과 워드클라우드 만드는 방법을 포스팅해보겠습니다.
고객리뷰 빈도수 분석을 통해, 해당 제품의 가장 큰 이슈, 특장점을 고객 입장에서 객관적으로 분석할 수 있겠죠?
워드클라우드를 통해 특장점을 한눈에 직관적으로 표현할 수 있습니다.
데이터 분석은 항상 재밌는 것 같아요!
내용에 오류가 있다면 댓글로 도움 주시면 감사하겠습니다! :)

'상품명', '리뷰' 두개의 값을 정리한 파일을 만들어줍니다.
저번시간 만들었던 리뷰데이터를 전부 복사해서 B2셀에 넣어주었습니다.
파일을 저장한 뒤 구글 드라이브에 업로드 해주면 됩니다.
저는 파일명 ('비욘드아쿠아.xlsx')로 해주었습니다.

구글 드라이브에 '화장품리뷰'라는 폴더를 만들고, 아까 저장한 엑셀 파일을 업로드 해주었습니다.
파이썬으로 코딩할 때, 파일명이 어려우면 실수할 수 있으므로 최대한 파일명을 간단하게 해주시면 좋아요.

구글 코랩을 실행하고, 새 노트를 만들어줍니다.

konlpy와 wordcloud 모듈을 설치해주세요

위 코드를 실행하시면, 나눔고딕으로 폰트가 설정됩니다.

구글 드라이브에 업로드한 파일에 접근하기 위해서, 마운트를 해줍니다.
제가 만든 폴더 '화장품리뷰'에 들어있는 파일 목록이 나옵니다.

구글드라이브 화장품리뷰 내에 '비욘드아쿠아.xlsx' 파일에 접근하여 데이터를 읽어오고,
df.head()를 통해 상위 몇개의 데이터를 출력해줍니다.
저는 상품명에 비욘드_아쿠아 1개의 제품만 넣어서 제품1개 데이터가 출력되었습니다.
다양한 제품 데이터를 엑셀 파일에 넣으셨다면 제품5개에 대한 데이터가 출력될 거에요 :)

만약 시트 여러개에 데이터를 넣으셨다면
위 코드를 통해 모든 시트의 데이터를 읽어올 수 있습니다.
표시된 'Sheet1'에 시트 명을 추가로 입력해주시면 됩니다.
['Sheet1', 'Sheet2', 'Sheet3'] 이렇게요!
저는 총 시트가 1개밖에 없기 때문에 df.list[0].head()는 데이터를 읽어오지만
df.list[1].head()는 데이터가 없어서 오류가 뜨네요

null값이 있다면 위의 코드를 통해 제거해줄 수 있습니다.
제 데이터에는 null값이 없었지만 필요하신분을 위해 올려드렸습니다.

os 모듈을 import 해주었습니다.
chdir 은 경로를 변경, 설정해주는 역할을 합니다.
konlpy가 있는 경로를 설정하고,
getcwd를 통해 현재 어떤 디렉토리(폴더)에 있는지 확인해줍니다.

현재 폴더(java)에 tmp 폴더를 만들어주고,
현재 경로를 tmp로 변경해주었습니다.
getcwd를 통하여 경로 변경이 잘 되었는지 출력하여 확인해봅니다.

ls 를 통해 상위폴더에 들어있는 파일 목록을 출력해줍니다.
open-korean-text-2.1.0.jar 파일 압축을 풀어줍니다.
현재 경로가 tmp로 설정되어있으니 압축 파일들이 tmp에 저장이 되겠죠?

분리되지 않을 단어가 저장된 파일을 불러오고 출력해주었습니다.
names +- '___\t' 를 통해 단어 추가를 더 해주었습니다.
저는 수분크림 관련 단어들을 추가해주었습니다.

names에 저장된 데이터를 원본 파일에도 저장해줍니다.

tmp 경로 설정해주고,
cvf로 아까 압축풀었던 파일을 다시 압축시켜줍니다.
오늘은 제품 한개에 대한 데이터 분석 방법을 알려드리겠습니다.
엑셀 파일에서 상품 목록이 많을 때 한꺼번에 분석하는 방법은 다음에 설명드리겠습니다.

one_text 에 오늘 분석할 리뷰 데이터를 넣어주었습니다. '리뷰'항목의 첫번째 데이터입니다.

Okt 메소드를 import 해줍니다.
okt는 형태소를 분석해주는 메소드입니다.
'제품이 너무 좋아요'라는 문장의 형태소를 분석해보았습니다.

nouns 로 문장을 토큰화해주고, one_text_tokenized 에 저장해주었습니다.
출력해서 토큰화된 것을 확인해주었습니다.

word_cloud_dict 딕셔너리를 만들어주었습니다. 이 데이터는 워드 클라우드를 만들 때 사용할 것입니다.
word_list 는 list(set())을 통해 토큰화된 데이터에서 중복 데이터를 제거하고 고유값으로 구성된 list 입니다.
word_cnt_list 는 단어 출현 횟수를 넣을 list 입니다.

tqdm 을 통해 반복문(for)의 진행 상황을 알 수 있습니다.
단어 글자수가 1일 경우 의미를 갖지 않는 경우가 많으므로 분석에서 pass를 해주었습니다.
for문에서 word_list (아까 정리한 고유값 데이터) 에 단어들 하나에 대한 데이터값을 계산하고, 저장해줍니다.
word_cnt 는 word가 토큰화된 데이터에서 몇번 중복해서 나타나는지 카운트해줍니다.
word_cnt를 word_cnt_list 에 list 형태로 추가를 해줍니다.
word_cnt는 word_cloud_dict 딕셔너리의 value 값에도 추가가 됩니다.

df_word_count 라는 새로운 데이터 프레임을 생성하고,
word 에는 word_list
word_cnt 에는 word_cnt_list 값을 넣어줍니다.
word_cnt에 대해 내림차순으로 정렬하고
빈도수 높은 30개 상위 데이터를 출력해주면, 빈도수 분석이 완료됩니다.
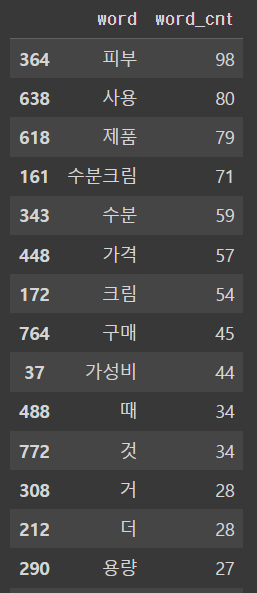

완성!
저는 리뷰를 많이 긁어오지 못해서 좀 아쉽지만 더더더 많이 긁어서 분석하면 더욱 정확도가 높아질 것 같습니다.
이 제품은 가성비가 좋고, 용량이 커서 듬뿍 바르는 고객이 많다는 인사이트를 얻었습니다. 뿌듯하네요!

워드클라우드 라이브러리를 불러오고, 규격을 설정해줍니다.

matplotlib 모듈을 불러와줍니다.

plt 에 대한 사이즈와 축 설정을 해주고 코드를 실행하면 워드클라우드가 완성됩니다.
저는 class101 꽃부리님의 강의를 활용해서 실습하고 있습니다. 파이썬 기본 개념(for문, if문, 등등) 이해하고계신다면 쉽게 배울 수 있어서 강추드립니다. 덕분에 실습 성공하였습니다 ㅎㅎ (광고 아닙니당 :)
https://class101.net/ko/products/62334b27a8866c000de7924f
개발자, 비개발자 모두 실무에 적용할 수 있는 자연어처리 입문 | 꽃부리AI
자연어처리가 모든 직군에게 다 필요하다고? ▶ 자연어처리 정의 컴퓨터로 언어를 연구하는 인공지능 분야인 자연어처리, 개발 직군이 아닌 마케터/기획자도 자연어처리를 배워야 한다구요? 네
class101.net
'데이터 분석' 카테고리의 다른 글
| 오픈 ai 챗gpt 프롬프트 작성 하는법 (0) | 2023.05.02 |
|---|---|
| NLP(자연어처리) 화장품 리뷰 분석 (3) Word2Vec / 단어별 유사도 유사어 찾기 (0) | 2023.02.07 |
| NLP(자연어처리) 화장품 리뷰 분석 (1)_데이터 준비 /크롤링 몰라도 가능 (1) | 2023.02.02 |


